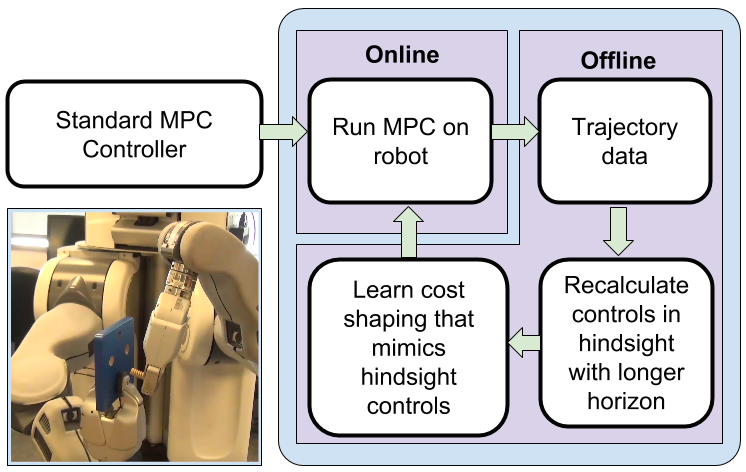
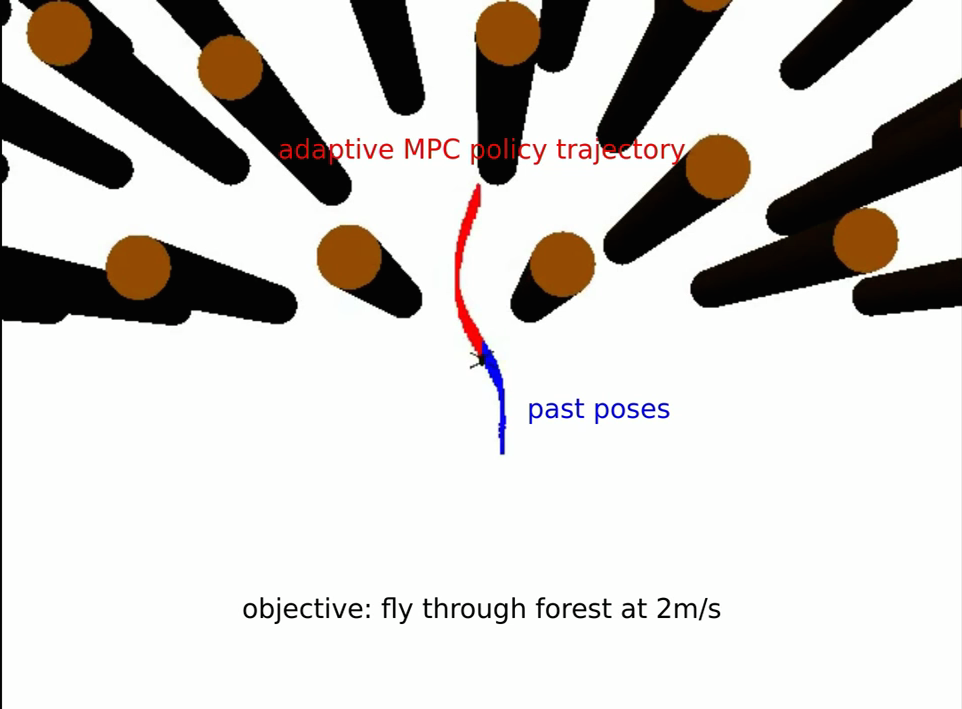
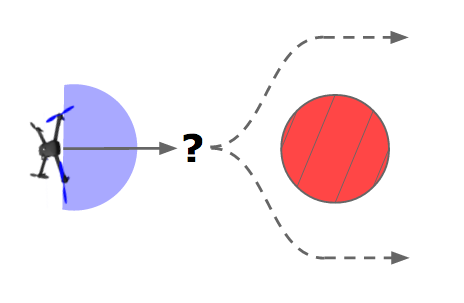
Building smart robots at covariant.ai (formerly, Embodied Intelligence). We are hiring!
Before co-founding covariant.ai, I was a PhD student in EECS at UC Berkeley, advised by Pieter Abbeel, where my interests are in Deep Learning, Reinforcement Learning and Robotics.
I received my bachelor's degree from UC Berkeley with double major in Computer Science and Statistics.